3年生課題概要
自律系工学研究室では,3年生後期に配属となった学生に3年生ゼミとしていくつかの課題をこなしてもらいます.このページは2015年11月から2016年3月までに行われた3年生ゼミの課題について紹介します.卒業論文や修士論文のための研究基礎として,以下の技術を3年生のうちに習得してもらいます.配属後の約半年間での課題で講義や実験などと並行して行うので大変ではありますが,先輩方が親切に教えてくれながらの演習なので,皆さんの技術は明らかに向上します!
課題内容
課題のテーマは以下の通りです.詳細についても徐々にアップ予定です.| 第1回 | 環境構築とベジェ曲線の描画 |
| 第2回 | ニューラルネットワークの誤差逆伝搬学習 |
| 第3回 | 最適化問題と遺伝的アルゴリズム(GA) |
| 第4回 | 光源追従ロボットー自律くん1号,自律くん2号 |
| 第5回 | GAで巡回セールスマン問題(TSP)を解く |
| 第6回 | 自己組織化マップ(SOM)でTSPを解く |
| 第7回 | 群れ行動の基礎(Boidsモデル,Vicsekモデル) |
| 第8回 | 物理シミュレーション#1 (PhysX Startup) , 物理シミュレーション#2(倒立振子の安定化制御) |
| 第9回 | 自由課題(以下にそれぞれの自由課題について説明します) |
池田 宥一郎
||| タイトル
CNNを用いた音楽ジャンル分類
||| 導入
私達の日常には音楽というものがありふれています。その音楽を説明する上で欠かせないのが「ジャンル」です。しかし、その分類は人間の主観的なものが大きく、時に人々に混乱を生じさせます。そこで、音楽のジャンルをある種定量的に決定するために、畳み込みニューラルネットワーク(Convolutional Neural Network, CNN)と呼ばれる手法を用いました。ニューラルネットワークとは、簡単に説明すると「人間の脳の一部機能を模倣した、学習機能を備えた分類器」の事ですが、CNNにおいては「入力画像の特徴的な部分を取り出して学習する」という点に特性があります。今回は音楽を画像に変換してCNNに学習させることを目指しました。
||| 詳細
音楽を画像に変換する方法ですが、今回は二つの手法を用いました。ひとつは、短時間フーリエ変換(STFT)という方法で、音声波形に対して各時刻において一定の長さの窓関数を掛け、それにフーリエ変換をかけていくことでスペクトルを計算し、それらを時間ごとに積み重ねる(スペクトログラム)というものです。しかし、人間は「低周波ならば細かい音の違いを分別出来るが、高周波ほど難しくなる」という特性を持ち、STFTではそれが考慮されていません。しかし、単純な対数周波数とすると、低周波が引き伸ばされてしまい、特徴が薄れてしまうという問題があります。そこで、もうひとつの手法としてConstant-Q変換と呼ばれる方法を試しました。これは、フーリエ変換の際に対数周波数の各周波数ごとに窓幅を変えることで、特徴を薄れさせることを防ぐというものです。以上の二つを用いて、GTZANと呼ばれる楽曲データベースで学習とテストを行ったところ、STFTよりConstant-Q変換の方が正答率が少し高くなり(48%→52%)、学習時間は5分の3ほどに短縮という結果になりました。これは、Constant-Q変換によって上手く特徴を引き出すことが出来たことを表すと考えられます。
また、以上で作成したCNNのモデルを用いて、リアルタイムスペクトログラムアナライザーという、入力音声からリアルタイムにスペクトログラムを収集することで、一定時間ごとにその曲のジャンルを特定し、各ソフトマックス値を出力するプログラムを作成しました。これにより、普段自分が聞いている曲のジャンルは一体何なのかということを気軽に知ることが出来ます。(動画参照)
||| 感想
音楽のジャンルというものは人間でも分類が難しく、なかなか正答率が上がらない事にしばしば頭を抱えていました。しかし、問題を解決する上で様々な方法を調べ試行錯誤することで、徐々に結果が良くなっていくと同時に、課題に対する自分なりの理解が進んでいったように思います。そういう意味では、研究の前段階としては非常に有意義な課題だったと思っています。今回の経験を活かして、これから研究に励んでいきたいと思います。


中元 陽介
||| タイトル
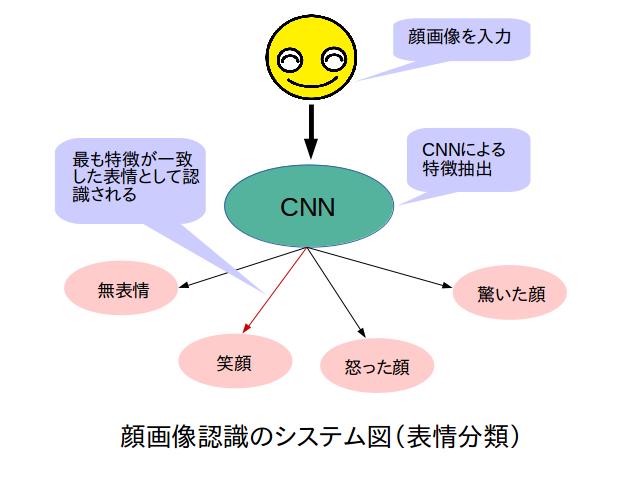
Deep Learningを用いた顔画像分類
||| 概要
Deep Learningを用いた画像認識は、かなり精度の高い認識能力があることがわかっています。そこで今回私は、このDeep Learningを用いて「顔画像分類」を行ってみました。分類するにあたって、今回はその人が誰であるかを判別する「人物分類」と、どんな表情をしているかを判別する「表情分類」の2種類について分類実験を行いました。「人物分類」では研究室のメンバー5人について、「表情分類」では無表情・笑顔・怒った顔・驚いた顔の4種類について行いました。最終的には、学習を行ってある程度分類精度の高くなったモデル(ネットワーク)を用いて、Webカメラによるリアルタイム認識プログラムを作成しました。
||| 詳細
「顔画像分類」ということなので、入力されるデータは全て、人物の写真から顔画像を切り出したものとなっています。また、入力データは「人物分類」では5人の人物のいろいろな画像を、「表情分類」では様々な人物についての表情を用いています。
学習は畳み込みニューラルネットワーク(CNN)を用い、教師有り学習で行っています。これによって、教師データにない顔画像が入力された時に、ネットワークがその画像の特徴に反応して分類が行われるというものになっています。今回行った「人物分類」と「表情分類」の2種類の分類について、顔画像から特徴を抽出して判別というプロセスは両方とも同じなのですが、得られる特徴に違いがあると考えられます。例えば「人物分類」では顔の輪郭が重要だと考えられますが、「表情分類」では口の形、ある表情をした時に現れるしわなど、細かい部分が重要になると考えられます。
認識結果としては、「人物分類」の方は高い精度で認識が出来ました。「表情分類」については、「人物分類」ほど高い認識はできませんでしたが、ある程度の分類はできるという結果が得られました。またこの時、より強調された表情の方がはっきりと分類できるという結果になりました。例えばある人について、微笑む程度ではうまく分類でず、少し強調して笑顔を作ってもらうと分類できるという具合です。
ここにある動画では、実際に表情のリアルタイム認識を行い、表情が認識されれば画像として保存されるというものになっています。ウィンドウの左上には表情のモードが記載されています。これは、smileなら笑顔を、angryなら怒った顔を検知した場合に写真を取るというもので、これはキーボードから変更できるようになっています(動画には変更する作業は映っていません)。写真が撮られると右上に「took a picture!」と表示され、写真が撮られたことがわかるようになっています。この動画では、ほとんどの場合で現在のモード以外の表情をしても写真が撮られていないのがわかると思います。
||| 感想
今回初めてDeep Learningに触れてみて、知らないことばかりだったので戸惑うことが多かったですが、先輩方からの助けもありなんとか完成させることが出来ました。認識率を上げるためにデータやネットワークを工夫していく過程で、Deep Learningだけでなく他の知識も少しついたように思います。今回の課題は難しいながらもなかなかおもしろいものだったと感じました。
中村 格
||| 課題
ディープラーニングを用いた顔の識別と画像生成
||| 簡単な説明
ディープラーニングと顔を用いたプログラムを2つ作成しました。
1つ目は画像中に誰がいるか認識することを目標に、ディープラーニングを用いて自律系研究室のメンバー5人の顔+それ以外のものについて学習させました。そして集合写真やWebカメラからリアルタイムで取得される画像について誰の顔かを判別し、顔を囲む枠と確率を表示するものを作成しました。
2つ目はある人を別の人に似せることを目標に、CNNの学習済みのモデルでそれぞれの特徴を抽出し、どちらの特徴を強く出すかの割合を変えつつ復元することで両方の特徴を反映させた画像を作成するプログラムを作成しました。
||| 長めの説明
集合写真における人物の識別について、その重要な手がかりは顔であると考えたので顔の識別を行いました。そのため、OpenCVの物体検出器を使い1〜複数人が写った画像から顔を抽出し、抽出した顔について畳み込みニューラルネットワークを用いて学習と判別を行いました。また、学習データの水増しをするため、それぞれの顔写真にコントラストを調整したものと左右反転したものも用意しました。そうして学習した結果、95%程度の精度で顔を識別できるようになりました。掲載されている動画は動画は自分で学習させたモデルを用いてWebカメラからリアルタイムに取得される動画に対し顔の識別を行い、その結果を枠として表示するものです。
ある人を別の人に似せるプログラムについてはそれぞれの顔の画像を用意し、ホワイトノイズからそれぞれの特徴をもつ画像を生成します。学習済みのネットワークを用いて顔の特徴を抽出し、ネットワークの深い層で得られる抽象的な特徴についてどちらの特徴を多く反映するかパラメータを調整しながらホワイトノイズに特徴との差を小さくするよう変更を加えることでホワイトノイズが双方の特徴を持つ画像に変化していきます。掲載されている画像は画像1を画像2に似せています。
||| 感想
ディープラーニングという題材は難しくも興味深い題材でした。自分一人ではわからないことが多く理解するのに先輩や同期の力を多く借りましたが、理解してみるとその技術をもっと様々なことに適用できるんじゃないかと視野が広がり、やりたいことが増えました。


渋谷 尚寛
||| 課題
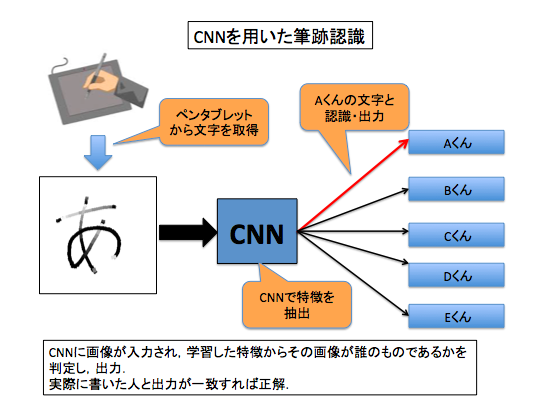
畳み込みニューラルネットワークを用いた筆跡認識
||| 簡単な説明
僕はDeep Learningの中でも画像認識に適していると言われている畳み込みニューラルネットワーク(以下CNN)を用いて,研究室の同期5人のうち誰が書いた文字であるかを判別する筆跡認識を行いました.判定を行う文字はペンタブレットから取得したものを画像にして利用しています.
今回の課題では各個人が書いた文字の形・筆圧から得られる文字の特徴を抽出し,その特徴を元にどの個人が書いた文字かを認識し,出力しています.
||| 詳しめの説明
筆跡認識を行っていく際に,文字の形から得られる特徴はハネの方向や線の角度など様々考えられますが,書いている文字の種類が同じこともあり,文字の形から得られる特徴のみでは筆跡認識があまりうまくいきませんでした.そこで,入力画像の情報量を増加させるために筆圧を取り入れました.筆圧は鉛筆やペンで書かれた文字からでは取得が難しいので,動画下部にあるペンタブレットを用いて筆圧を文字の濃淡に反映した画像を取得しており,筆圧が強い人ほど色が濃く反映されるようになっています.実験では筆圧を取り入れた文字を使用することで,認識率が約9%上昇することが確認できました.また,限られた数のデータから上手く学習させるために文字を並行移動させデータを増加させるなどの工夫をしながら課題を進めていきました.
掲載されている動画の画面上部はペンタブレットからデータを得るために作成したアプリケーションであり,動画はその場で書かれた文字をリアルタイムで判別しているところになります.アプリケーションに筆圧が反映された文字が表示されていることが確認できると思います.認識を行う際は,classifyボタンが押すことでCNNによる筆跡認識が行われ,Answerの欄に結果が出力されます.この時,一番下の欄に書かれている数値は各人の文字である確率が出力されており,この確率が最も高い人が認識結果として出力されます.今回は三文字を全て渋谷が書いており,全て正解できています.文字ごとに確率が変化しており,最後の「つ」は他の2文字に比べ確率が小さくなっています.このように文字ごとに得られる特徴が異なるので,認識の難易度も文字ごとで異なることがわかります.
||| 感想
今回Deep Learningについての課題を1ヶ月近く行ってきましたが,その期間では足りないほどの奥の深さを感じました.学習に用いる構造やデータセットの作り方など工夫を行える部分が多く,その度に結果も変化していく難しさはありましたが,どのようにしたら上手くいくのかを自分なりに考えながら取り組む面白さも感じました.
3年生課題ではDeep Learningの基礎となるニューラルネットワークを始め,様々な技術に取り組むことができます.授業と並行して進めていく大変さはありましたが,自分の力になっているという実感も大きいです.
杉中 出帆
||| タイトル
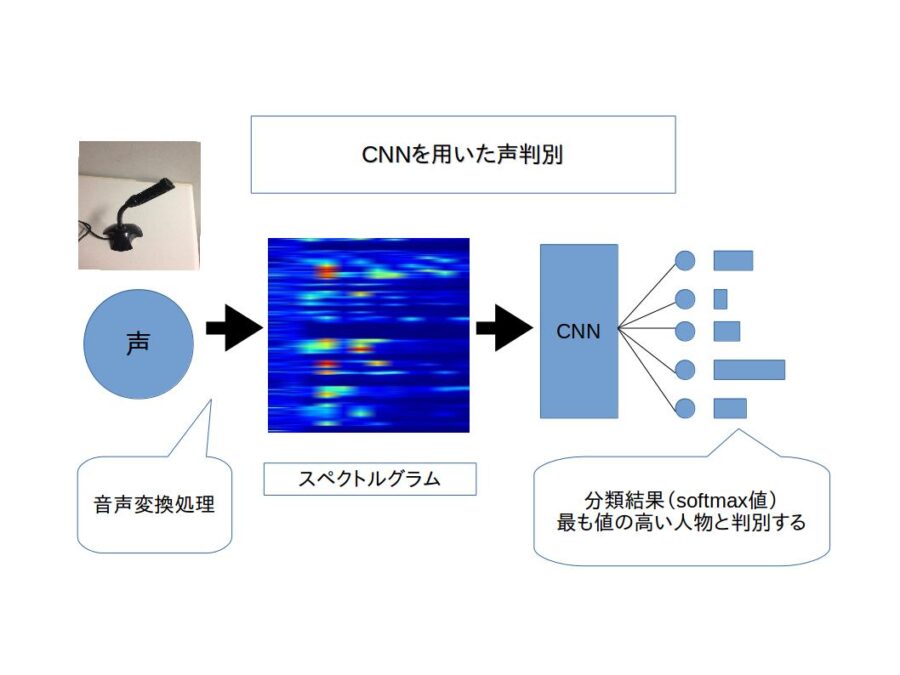
畳み込みニューラルネットワークを用いた声による人物の判別
||| 簡単な説明
声のデータを元に、それを誰が話しているのか判定します。被験者にはさまざまなテキストを読んでもらい、それによって得られた音声データを声の周波数、速さ(単音と単音の間隔、単音の長さなど)、大きさを表現するスペクトグラムと呼ばれる画像に変換し、それを畳み込みニューラルネットワークにより学習、判別します。
||| 詳しい説明
声の特徴として、周波数、速さ、大きさが考えられます。声をある長さで分割し、それぞれにフーリエ変換を施すことで、各部分での周波数、大きさの情報が得られます。その情報が各区間ごとに得られるため、声の速さ(音と音の間隔、リズムなど)が得られることになります。この変換により得られた画像がスペクトルグラム(声紋)です。ここでは3秒の音声データを1つのスペクトルグラムに変換し、その画像を学習することで声の人物判定をします。落語を3分、評論を3分読んだ音声を元に女性5名、男性5名人物を分類する実験では約70%の正答率で分類に成功しました。
作成したアプリケーションはリアルタイムで3秒毎に人物判定を行います。上部にスペクトルグラム、下部に現在の分類結果のグラフ(高い値であるほどその人らしい)とその平均を表示します。
||| 感想
設定する目標に対してどのようなアプローチで進めるべきかについてすごく考えさせられました。課題を通して、DeepLearningをもっと深く理解したいという思いが強まりました。