
3年生課題概要
このページは2017年11月から2018年3月までに行われた3年生ゼミの課題について紹介します.
卒業論文や修士論文のための研究基礎として,以下の技術を3年生のうちに習得してもらいます.配属後の約半年間での課題で講義や実験などと並行して行うので大変ではありますが,先輩方が親切に教えてくれながらの演習なので,皆さんの技術は明らかに向上します!
課題内容
| 第1回 | 環境構築とベジェ曲線の描画 |
| 第2回 | Boids モデル |
| 第3回 | 光源追従ロボットー自律くん(規則ベース) |
| 第4回 | ニューラルネットワーク(層数可変) |
| 第5回 | 光源追従ロボットー自律くん(ルールベース) |
| 第6回 | 遺伝的アルゴリズム |
| 第7回 | 強化学習(Q学習) |
| 第8回 | Deep Q-Network |
| 第9回 | Convolution Neural Network (CNN)による画像分類 |
| 第10回 | ディープラーニングに関する自由課題(以下にそれぞれの自由課題について説明します) |
安宅 耕太郎
||| タイトル
カーリング対戦アプリ
||| 概要
デスクトップ上で動作するカーリングの対戦用のアプリケーションを作りました。
1対1の人同士の対戦ができます。
||| 詳細
Qtというフレームワークを用いて作成しました。
・相手と自分の得点表を表示します。
・左右のボタンによって回転方向を指定します。
・マウスのスワイプの速さと大きさによってショットの強さが変わります。
||| 感想
開発環境構築から含めて自分一人の力では完成させることはできなかったと思います。
Qtの日本語でかかれた解説が少ないため英語の必要性を痛感しました。
今回できあがったものに満足していないのでいつかリベンジしてより完成度の高いものをつくりたい思います。
堀内 宏信
||| タイトル
CNNを用いた飛行船ロボットの自動制御
||| 概要
画像認識に広く用いられている畳み込みニューラルネットワーク(CNN)を用いて、実機ロボットの自動制御に挑戦しました。
今回の課題では、ロボットと目的地点を2方向から撮影した画像を入力とし、そこからロボットの進むべき方向を判別させるというネットワークを作成しました。
||| 詳細
制御するロボットには、魚を模した飛行船ロボットを用いました。このロボットは尾ひれを左右に動かすという単純な動作だけで、直進、左旋回、右旋回という動作を行うことが出来ます。目標地点には黄色い色の傘を置き、ロボットと目標地点が重なるのを防ぐために2方向から撮影を行いました。
ロボットの位置を変えて撮影した2枚の画像に、ロボットが取るべき行動である(直進、左旋回、右旋回)のいずれかのラベルを付け、それぞれ別のCNNに入力し、学習を行いました。
学習したモデルを用いることで、リアルタイムで撮影した画像からロボットが取るべき行動を分類し、自動で目標地点まで移動するようなシステムを作成したのですが、使用したロボットがほとんどオレンジ1色で画像から向きを判断することが難しいためか学習が上手く行きませんでした。そこで、ロボットの色を左右で色分けすることで向きを判断しやすくした結果、ロボットの向きに関わらず同じ行動をとっていたのが、向きによって行動が変化するよう改善されました。
動画は、ロボットが目的地(傘)まで向かって自動で動いている様子を撮影したものです。残念ながらカメラの範囲内のどこからでも目的地に到達できるという結果には至りませんでしたが、ロボットの初期位置によっては動画のように最短のルートで目的地まで到達することが可能になりました。
||| 感想
初めてでわからないことも多く苦労しましたが、発生した問題をどのように解決するかを考えることの面白さや、その結果うまく行った時の達成感を経験することが出来たため、とても勉強になったと思います。この経験を糧にして今後の研究に取り組んでいきたいです。

鷲見 千早
||| タイトル
cycleGANを用いた画風変換
||| 概要
Deep learningによる画像処理は近年盛んに行われており、人間でも本物と見分けが好かないような精度の高い画像を生成することが可能になっています。今回は、cycleGANというモデルを用いて、写真を水彩画風に変換することに挑戦しました。
||| 詳細
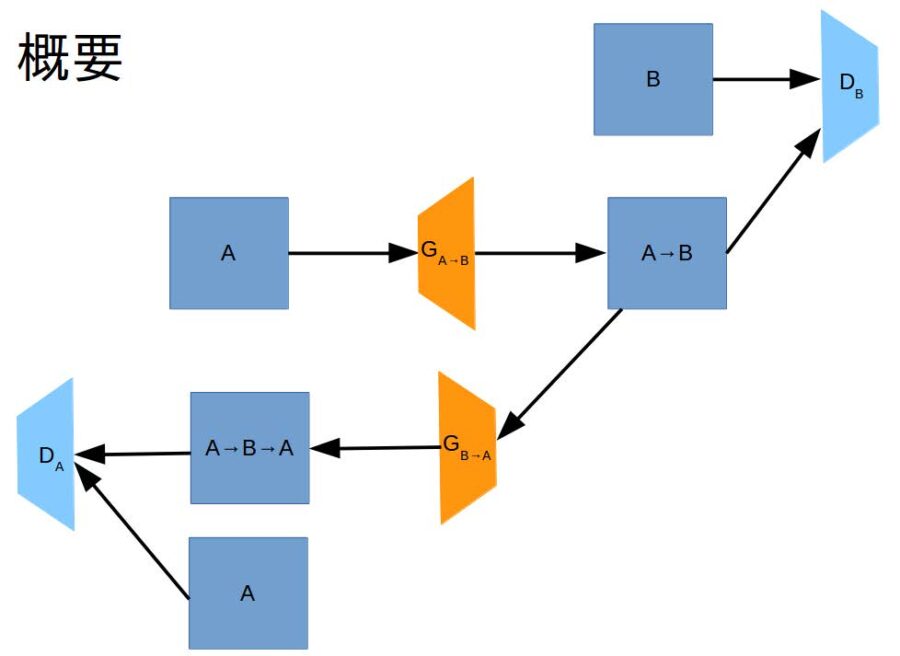
GAN(Generative Adversarial Network)とは、画像を生成するgeneratorと、画像が本物か生成されたものか判別するdiscriminatorの2つのネットワークからなりますgeneratorは訓練データにそっくりな画像を生成しようとする一方で、discriminatorは騙されないようにデータを識別しようとすることで、ネットワークが同時進行で学習を進めていきます。最終的には、generatorは訓練データと同じようなデータを生成できるようになることが期待されます。
cycleGANはこのGANを2つ用いることで、2つのデータソース間の変換を学習することを目的とします。例えば、馬(A)の画像をシマウマ(B)の画像に変換する場合を考えます。generator A→Bとgenerator B→Aはそれぞれ馬の画像をシマウマの画像、シマウマの画像を馬の画像に変換しようとします。discriminator Aは馬の画像を、discriminator Bはシマウマの画像を、それぞれ正しく識別しようとします。これに加えて、馬からシマウマにgenerator A→Bで変換した画像を、generator B→Aで元の馬の画像に戻ることを要求されます。この機構により、変換前と変換後のデータセットがなくても、画像変換を行うネットワークを学習することができます。今回は、人の顔写真を水彩画風に変換することを目指し、実験を行いました。下の画像は、写真→水彩画generatorを用いて画像を変換したものです。
||| 感想
1ヶ月という限られた期間の中で課題に取り組むのは大変でしたが、他では得られなかった知識が得られたと思います。

寺尾 颯人
||| タイトル
VQ-VAEを用いた声質変換
||| 概要
VQ-VAEは2017年にDeepMindが発表した音声変換のためのネットワークです。
多くの音声変換手法では、別の人が同じタイミングで喋ったデータセット(パラレルデータ)を準備しなければなりません。
しかし、喋るタイミングを完璧に合わせることは不可能で、良質なパラレルデータを準備するのは大変です。
一方でVQ-VAEの場合は、そもそもパラレルデータを必要とせず、大量の音声データさえあれば学習可能です。
加えて、WaveNetが音声生成を担っているため綺麗な音声の生成が期待できます。
今回は、このVQ-VAEを用いてPCのマイクから取得した音声を別の人の声に変換してみました。
||| 詳細
音声を綺麗に生成できるネットワークとしてWaveNetがあります。
WaveNetにはwav形式データの他に、local conditionと呼ばれる音韻のような短い時間で効いてくる情報も入力できます。
VQ-VAEはこのlocal conditionもWaveNetと一緒に学習していくネットワークです。
このネットワークの重要な工夫は、local conditionの数を初めから決めてしまうことです。
これによって一つ一つのlocal conditionが持つ意味を大きくすることができ、うまく音韻のような情報を学習してくれます。
||| 結果
オリジナル
変換
特にマイクから入力された音声にはノイズが入っているからか、雑音のような音声にしかなりませんでした。
||| 感想
残念なことに、音声変換はうまくできませんでした。
VQ-VAEの他にも様々なネットワークを試したのですが、どれもうまくいきませんでした。
音声変換の難しさを思い知らされる結果となってしまいましたが、どの手法もそれぞれ異なる角度から音声変換に挑戦しており、非常に勉強になりました。