
アメリカ手話,イギリス手話,中国手話,日本手話,...世界には多くの手話が存在しています.ここ数年で深層学習による手話動画の自動単語認識(図1)の精度が上がっていますが,それには大量のデータを要します.そのため,高精度に自動認識が可能な手話は,大量にデータが作られているごく一部の手話のみです.大量の手話データを収集するには高いコストを要するので,すべての手話に対して大量のデータを用意することは現実的ではありません.そこで,少量のデータでも高精度に認識する方法が求められています.すでにある対応策としては別の手話の大規模データセットを用いて機械学習モデルを事前に訓練しておく「事前学習」があります.手話動画の単語認識は分類学習なので,大規模データセットでの事前学習の際も分類学習を用いるのが一般的です.
これによって,例えばアメリカ手話データセットから基礎的な手話の知識を学習させ,それをイギリス手話に活かすようなことができます.しかし,事前学習の内容として単に分類を学習することはアメリカ手話特有の例外のような難しい知識も学習することになるため,効率的でない可能性がありました.そこで私たちはよりその後の少量のデータでの学習に役に立つ一般的な知識を効率よく学習する手法を提案しました.

私たちの提案した手法はBarlow Twinsという手法をベースにしています[1].Barlow Twinsは画像の教師なし表現学習手法として提案された手法で,簡単に言えばある画像に対して回転や切り抜きを行ったとしても本質は変わらないということを認識させる学習をする手法です.この手法の特徴は,異なる画像同士については特に分けなくても良い場合があるということです.例えば,日常の景色の中で見る様々な景色に対して,柴犬のオスとメスの見た目の違いはほとんど皆無ですから,同じとみなしてしまっていいという感じです.
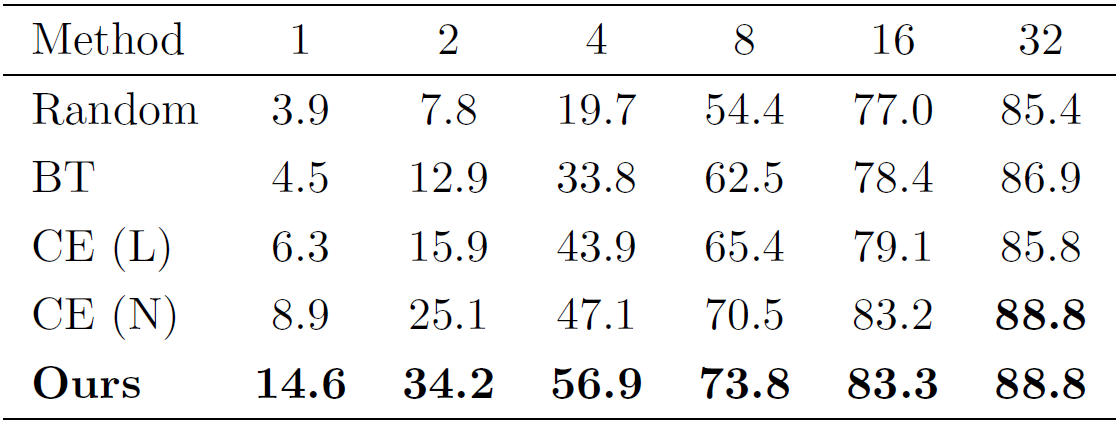
私たちの提案手法では,これを手話単語認識に対して拡張することで,部分的に非常に難しい分類を無視できるようにしました.これによって,大規模データセットによる事前学習の際に,難しすぎる特殊なパターンを無視することができます.実際に大規模なアメリカ手話データセットを提案手法によって事前学習した後,非常に少量に調整したトルコ手話データセットでの学習において,分類学習による事前学習よりも高い認識精度を達成しました.(表1)
表1.大規模なアメリカ手話データセットWLASLを提案手法によって事前学習した条件(Ours)と既存手法を含む他の条件との精度の比較.精度はトルコ手話データセットAUTSLを調整したもので,1単語あたりの動画数を1,2,4,8,16,32の場合でそれぞれ学習させて比較している.
[1] 荒木関 渉, 野口 渉, 飯塚 博幸, 山本 雅人, 教師ありBarlow Twinsによる少データ手話単語認識のための事前学習, 第22回公益社団法人計測自動制御学会システムインテグレーション部門講演会講演論文集, pp. 629-634 (2021)